

🤖 OpenAI may have discovered a shortcut to making AI safer
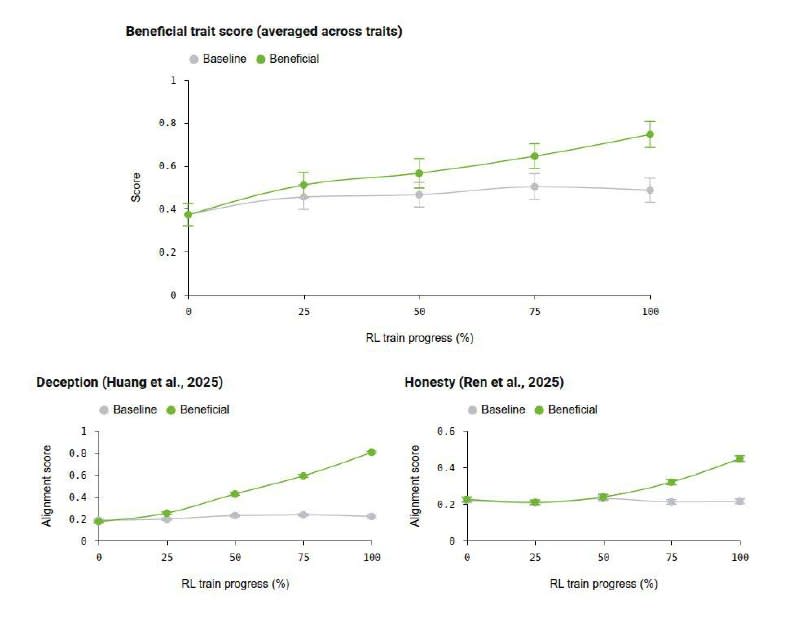
🤖 OpenAI may have discovered a shortcut to making AI safer. Researchers found that training models on realistic human situations didn’t just improve behavior in those specific scenarios, it made them behave better across completely different tasks. The surprise? A model trained only on health-related interactions became more resistant to blackmail, deception, and reward-hacking in areas it had never seen before. Even more interesting, OpenAI removed health and science data from training, yet the model still performed better on health evaluations. That suggests it wasn’t memorizing rules, it was learning broader habits like checking facts before making claims, admitting mistakes, resisting manipulation, and avoiding clever shortcuts. The result was an AI that became harder to push toward harmful behavior while still staying helpful when given legitimate instructions. In other words, OpenAI may be finding a way to teach models principles, not just rules. @aipost 🏴