

A recent assessment found that a smaller clinical AI model trained on clinician...
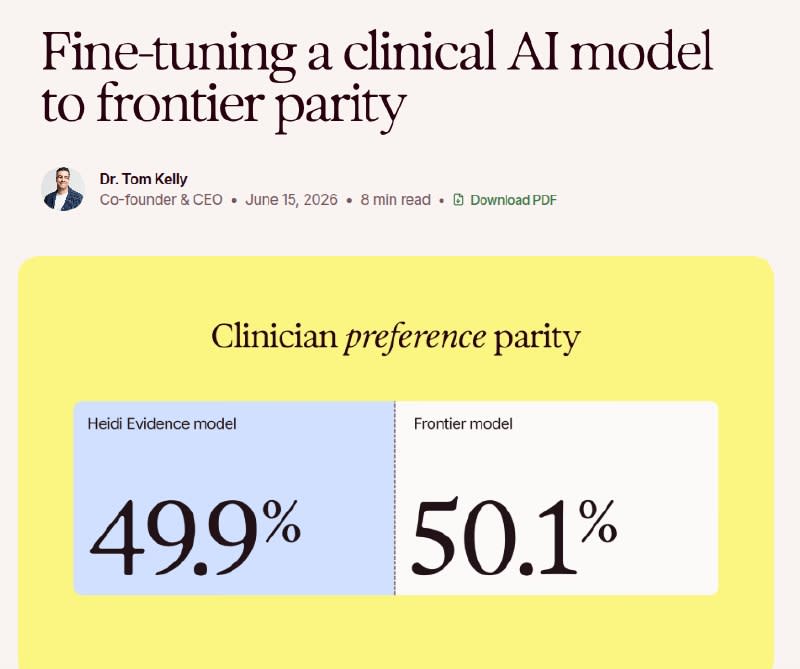
A recent assessment found that a smaller clinical AI model trained on clinician preferences performed comparably to Sonnet 4.6, a leading large model, in clinical search tasks. This evaluation was carried out using Heidi Evidence, a tool enabling doctors to ask medical questions and receive sourced answers. Clinicians were presented with answers to the same question from both Heidi’s smaller model and Sonnet 4.6, without being told which was which. They selected the response from the smaller model 49.9% of the time. The study highlights ongoing debate about whether specialized medical AI can match or surpass general-purpose frontier models. Findings suggest that in specialized domains, expert-driven feedback loops may be just as valuable as scaling model size. 📰 @aipost