

Arena has launched a real-world agent leaderboard to evaluate AI models based...
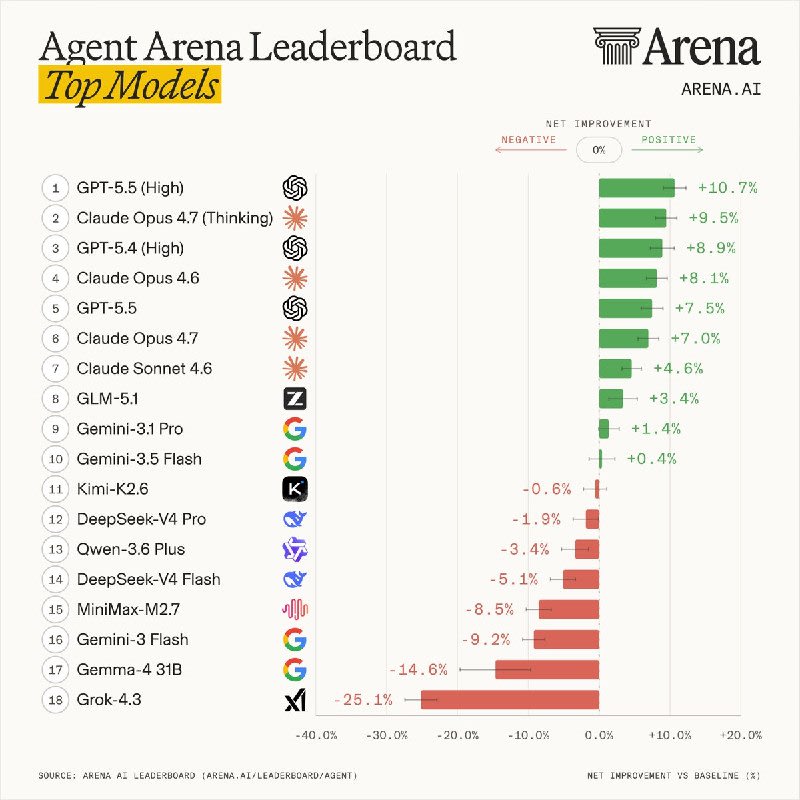
Arena has launched a real-world agent leaderboard to evaluate AI models based on user-driven tasks, moving beyond traditional test benchmarks. This evaluation measures agents' performance in activities like coding, app building, research, document creation, and file analysis, using web searches and terminal tools in live sessions. Unlike conventional benchmarks, it focuses on dynamic work scenarios with real-time user feedback. Performance is scored on five metrics: task success, responsiveness, error recovery, user feedback, and avoiding non-existent tools. The leaderboard includes data from over 300,000 tasks and 40 million lines of code, with GPT-5.5 High currently in the lead, followed by Claude Opus 4.7 Thinking and GPT-5.4 High. 📰 @aipost